¶ 优先级规则
优先级规则分为:订阅优先级、搜索优先级、洗版优先级,按如下规则应用:
- 不设置优先级规则时,默认不使用优先级规则过滤。
- 按规则先后顺序依次匹配,使用匹配通过的第一个规则作为该资源的优先级。如果所有规则均不匹配,则该资源会被过滤。
- 资源的匹配优先级越高(数字越小),则搜索和下载排序会在前面,最有可能会被下载。
- 规则中的各规则项是
与的关系,同类型规则项不能同时选择,比如分辨率:1080P和分辨率:4K不能同时选择,是不可能同时匹配通过的。 - 需要全局排除一个规则项时,所有优先级规则中都需要排除这项,否则不能实现全局排除的目的。
¶ 示例
优先特效字幕、中文字幕,排除杜比和蓝光原盘,仅限4K和1080P,1080P优先:
SPECSUB & !BLU & !DOLBY & 1080P > CNSUB & !BLU & !DOLBY & 1080P > SPECSUB & BLU & !DOLBY & 4K > CNSUB & !BLU & !DOLBY & 4K
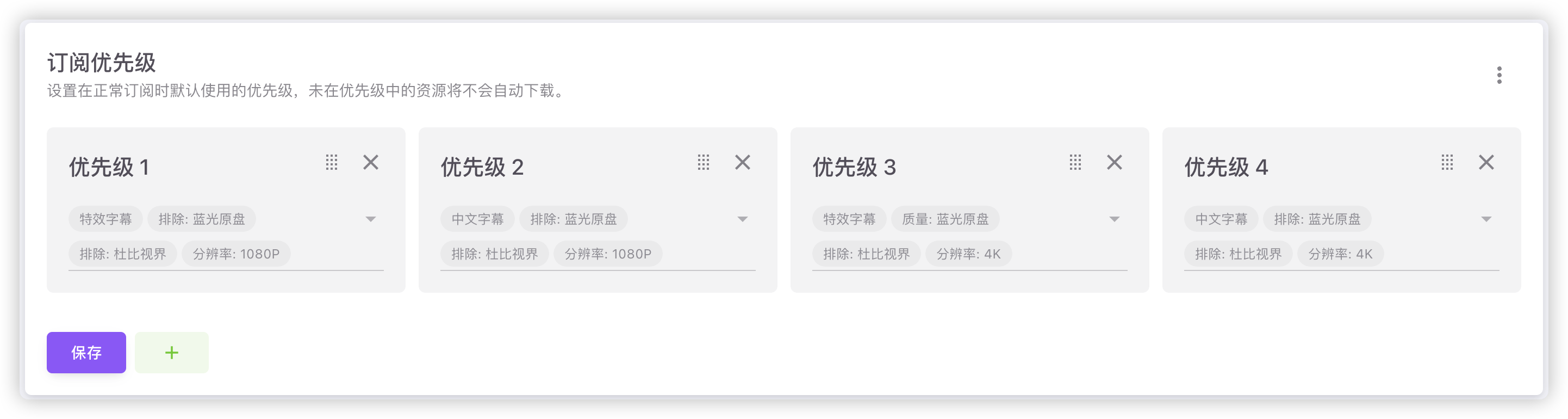
其中中文字幕规则只针对非国产电影和剧集生效。
¶ 分享
点击优先级右上角按钮,选择分享,可将优先级规则复制到剪切板,选择导入可以快速导入别人分享的优先级规则。
¶ 自定义识别词
对于命名不规范的资源,可以在设定 -> 词表中编写自定义识别词,使用正则表达式对资源名称进行校正,以便MoviePilot可以正确识别。
V2版本中支持在订阅中设定该订阅专用的识别词,同时可以将该订阅分享出去,让其他MPer参考订阅。
自定义识别词支持以下几种配置格式(注意连接符号左右的空格):
- 屏蔽词
- 被替换词 => 替换词
- 前定位词 <> 后定位词 >> 集偏移量(EP)
- 被替换词 => 替换词 && 前定位词 <> 后定位词 >> 集偏移量(EP)
其中:
屏弊词:将该词从待识别文本中去除。替换词支持特定格式:{[tmdbid/doubanid=xxx;type=movie/tv;s=xxx;e=xxx]},直接指定TMDBID/豆瓣ID识别,其中s、e为季数和集数(可选),使用这种模式时,注意不要把资源的原标题替换掉了。集偏移:定位待识别文本中的集数位置,并对识别出来的集数做运算,以解决识别出来的的集数与TMDB实际不一致的问题。前后定位词之间的所有数字(包括中文小写,不包括中文大写)视为集数,偏移集数支持运算,例如集数加1:EP+1;集数翻倍:2*EP;集数翻倍-1:2*EP-1(EP代表原集数)。
¶ 示例
以下链接中有相关的示例,可通过共享识别词插件自动更新到本地使用:
- https://movie-pilot.org/etherpad/p/MoviePilot_TV_Words
- https://movie-pilot.org/etherpad/p/MoviePilot_Anime_Words
以上链接为大家自觉共享维护使用,请勿添加未充分识别测试的内容,请不要恶意破坏!
如果你使用了以上共享识别时,同时发现MoviePilot识别出现问题,一些本应该识别的都无法正常识别,有可能是共享识别词中出现了一些错误的内容导致。
¶ 自定义重命名
MoviePilot文件重命名格式定义基于jinja2语法,关于语法的内容可参考 模板引擎Jinja2语法介绍。
可根据以下可配置项说明,参考默认的格式配置,调整命名格式:
- 以
/分隔多级目录,可调整目录名和文件名格式。 - 在使用一个变量前,建议增加
if判定语句,变量不为空时才拼装。
V2版本中可以直接在前端界面中设置
重命名格式支持的通用配置项:
| 配置项 | 说明 |
|---|---|
title |
TMDB/豆瓣中的标题 |
en_title |
TMDB中的英文标题(暂不支持豆瓣) |
original_title |
TMDB/豆瓣中的原语种标题 |
name |
从文件名中识别的名称(同时存在中英文时,优先使用中文) |
en_name |
从文件名中识别的英文名称(可能为空) |
original_name |
原文件名(包括文件后缀) |
year |
年份 |
title_year |
标题和年份,如 电影名 (2024) |
type |
媒体类型,如电影、电视剧 |
category |
媒体分类 |
vote_average |
评分 |
poster |
海报图片地址 |
backdrop |
背景图片地址 |
actors |
演员,最多取前5位 |
overview |
简介 |
resourceType |
资源类型 |
effect |
特效 |
edition |
版本(资源类型+特效) |
videoFormat |
分辨率 |
resource_term |
质量(资源类型+特效+分辨率) |
releaseGroup |
制作组/字幕组 |
videoCodec |
视频编码 |
videoBit |
视频位深,如 8bit、10bit |
audioCodec |
音频编码 |
fps |
帧率 |
webSource |
流媒体平台 |
tmdbid |
TMDB ID(非TMDB识别源时为空) |
imdbid |
IMDB ID(可能为空) |
doubanid |
豆瓣ID(非豆瓣识别源时为空) |
part |
段/节 |
fileExt |
文件扩展名,如 .mkv |
customization |
自定义占位符 |
例如需要在文件名中加入视频编码和位深,可写为:
{{title}}{% if year %} ({{year}}){% endif %}/{{title}}{% if year %} ({{year}}){% endif %}{% if videoCodec %} - {{videoCodec}}{% endif %}{% if videoBit %} {{videoBit}}{% endif %}{{fileExt}}
TV_RENAME_FORMAT额外支持的配置项:
| 配置项 | 说明 |
|---|---|
season |
季号数字 |
season_fmt |
季号格式,如 S01 |
season_year |
季年份 |
episode |
集号或集号范围 |
season_episode |
季集,如 S01E02 |
episode_title |
集标题 |
episode_date |
集播出日期 |
¶ 多目录支持与分类
设定 中可统一设定下载和媒体库目录,可添加多个目录配置项,系统按先后顺序依次匹配,匹配到的第一个附合条件的目录做为使用目录。通过拖动卡片调整目录项的优先顺序,一般情况下需要细化的目录需要调整到前面才能生效。
下载目录和媒体库目录均支持两级分类体系:
- 一级分类为
媒体类型,固定分为:电影、电视剧。 - 二级分类为
媒体类别,通过分类策略结合TheMovieDb的元数据确定分类。
目录设置时请关注以下特性:
媒体类型和媒体类别为使用这个目录的判定条件,按媒体的元数据进行匹配,全部代表匹配通过。自动分类只有在媒体类型和媒体类别至少其中一个为全部时才会生效。- 当
自动分类为关时,目录以设置的路径为准,不会自动创建子目录。 - 当
自动分类为开时:- 如果
媒体类型为全部、媒体类别为全部,会自动在设定路径下生成一级分类目录和二级分类目录; - 如果
媒体类型不为全部、媒体类别为全部,会自动在设定路径下创建二级分类目录; - 如果
媒体类型不为全部、媒体类别不为全部,以设定路径为准不会自动创建子目录。
- 如果
¶ 二级分类策略
可以通过编辑 /config/category.yaml 文件来自定义二级分类策略,也可以通过插件二级分类策略编辑。
以下为默认的二级分类策略配置文件,结合说明可自定义二级分类:
# 配置电影的分类策略
movie:
# 分类名同时也是目录名
动画电影:
# 匹配 genre_ids 内容类型,16是动漫
genre_ids: '16'
华语电影:
# 匹配语种
original_language: 'zh,cn,bo,za'
# 未匹配以上条件时,分类为外语电影
外语电影:
# 配置电视剧的分类策略
tv:
# 分类名同时也是目录名
国漫:
# 匹配 genre_ids 内容类型,16是动漫
genre_ids: '16'
# 匹配 origin_country 国家,CN是中国大陆,TW是中国台湾,HK是中国香港
origin_country: 'CN,TW,HK'
日番:
# 匹配 genre_ids 内容类型,16是动漫
genre_ids: '16'
# 匹配 origin_country 国家,JP是日本
origin_country: 'JP'
纪录片:
# 匹配 genre_ids 内容类型,99是纪录片
genre_ids: '99'
儿童:
# 匹配 genre_ids 内容类型,10762是儿童
genre_ids: '10762'
综艺:
# 匹配 genre_ids 内容类型,10764 10767都是综艺
genre_ids: '10764,10767'
国产剧:
# 匹配 origin_country 国家,CN是中国大陆,TW是中国台湾,HK是中国香港
origin_country: 'CN,TW,HK'
欧美剧:
# 匹配 origin_country 国家,主要欧美国家列表
origin_country: 'US,FR,GB,DE,ES,IT,NL,PT,RU,UK'
日韩剧:
# 匹配 origin_country 国家,主要亚洲国家列表
origin_country: 'JP,KP,KR,TH,IN,SG'
# 未匹配以上分类,则命名为未分类
未分类:
二级分类策略配置说明:
- 该配置文件用于配置电影和电视剧的分类策略,配置后程序会按照配置的分类策略名称从上到下依次匹配确定分类,配置文件采用
yaml格式,需要严格附合语法规则。 - 配置文件中的一级分类名称:
movie、tv为固定名称不可修改,二级名称同时也是目录名称,会按先后顺序匹配到后程序会按这个名称建立二级目录。 - 同一个分类名称下的多个判定条件为
与的关系,一个判定条件内的多个值是或的关系,通过,连接。支持的判定条件有: - !条件值表示排除该值,一般用于将分类中的某子类单独分类的情况,同时不用考虑分类先后顺序
genre_ids 内容类型字典:
# 注意部分中英文是不一样的
# 28 Action
# 12 Adventure
# 16 Animation
# 35 Comedy
# 80 Crime
# 99 Documentary
# 18 Drama
# 10751 Family
# 14 Fantasy
# 36 History
# 27 Horror
# 10402 Music
# 9648 Mystery
# 10749 Romance
# 878 Science Fiction
# 10770 TV Movie
# 53 Thriller
# 10752 War
# 37 Western
# 28 动作
# 12 冒险
# 16 动画
# 35 喜剧
# 80 犯罪
# 99 纪录
# 18 剧情
# 10751 家庭
# 14 奇幻
# 36 历史
# 27 恐怖
# 10402 音乐
# 9648 悬疑
# 10749 爱情
# 878 科幻
# 10770 电视电影
# 53 惊悚
# 10752 战争
# 37 西部
original_language语种字典:
# af 南非语
# ar 阿拉伯语
# az 阿塞拜疆语
# be 比利时语
# bg 保加利亚语
# ca 加泰隆语
# cs 捷克语
# cy 威尔士语
# da 丹麦语
# de 德语
# dv 第维埃语
# el 希腊语
# en 英语
# eo 世界语
# es 西班牙语
# et 爱沙尼亚语
# eu 巴士克语
# fa 法斯语
# fi 芬兰语
# fo 法罗语
# fr 法语
# gl 加里西亚语
# gu 古吉拉特语
# he 希伯来语
# hi 印地语
# hr 克罗地亚语
# hu 匈牙利语
# hy 亚美尼亚语
# id 印度尼西亚语
# is 冰岛语
# it 意大利语
# ja 日语
# ka 格鲁吉亚语
# kk 哈萨克语
# kn 卡纳拉语
# ko 朝鲜语
# kok 孔卡尼语
# ky 吉尔吉斯语
# lt 立陶宛语
# lv 拉脱维亚语
# mi 毛利语
# mk 马其顿语
# mn 蒙古语
# mr 马拉地语
# ms 马来语
# mt 马耳他语
# nb 挪威语(伯克梅尔)
# nl 荷兰语
# ns 北梭托语
# pa 旁遮普语
# pl 波兰语
# pt 葡萄牙语
# qu 克丘亚语
# ro 罗马尼亚语
# ru 俄语
# sa 梵文
# se 北萨摩斯语
# sk 斯洛伐克语
# sl 斯洛文尼亚语
# sq 阿尔巴尼亚语
# sv 瑞典语
# sw 斯瓦希里语
# syr 叙利亚语
# ta 泰米尔语
# te 泰卢固语
# th 泰语
# tl 塔加路语
# tn 茨瓦纳语
# tr 土耳其语
# ts 宗加语
# tt 鞑靼语
# uk 乌克兰语
# ur 乌都语
# uz 乌兹别克语
# vi 越南语
# xh 班图语
# zh 中文
# cn 中文
# zu 祖鲁语
origin_country/production_countries 国家地区字典:
# AR 阿根廷
# AU 澳大利亚
# BE 比利时
# BR 巴西
# CA 加拿大
# CH 瑞士
# CL 智利
# CO 哥伦比亚
# CZ 捷克
# DE 德国
# DK 丹麦
# EG 埃及
# ES 西班牙
# FR 法国
# GR 希腊
# HK 香港
# IL 以色列
# IN 印度
# IQ 伊拉克
# IR 伊朗
# IT 意大利
# JP 日本
# MM 缅甸
# MO 澳门
# MX 墨西哥
# MY 马来西亚
# NL 荷兰
# NO 挪威
# PH 菲律宾
# PK 巴基斯坦
# PL 波兰
# RU 俄罗斯
# SE 瑞典
# SG 新加坡
# TH 泰国
# TR 土耳其
# US 美国
# VN 越南
# CN 中国 内地
# GB 英国
# TW 中国台湾
# NZ 新西兰
# SA 沙特阿拉伯
# LA 老挝
# KP 朝鲜 北朝鲜
# KR 韩国 南朝鲜
# PT 葡萄牙
# MN 蒙古国 蒙古
¶ 目录配置示例
各分类场景示例:
* 假设根目录为:/video
1、需要一二级自动分类
- 路径:/video
类型:全部
类别:全部
自动分类:开
2、一级手动分类,二级自动分类
- 路径:/video/电影
类型:电影
类别:全部
自动分类:开
- 路径:/video/电视剧
类型:电视剧
类别:全部
自动分类:开
3、一级手动分类,二级不分类
- 路径:/video/电影
类型:电影
类别:全部
自动分类:关
- 路径:/video/电视剧
类型:电视剧
类别:全部
自动分类:关
4、不需要分类
- 路径:/video/其它
类型:全部
类别:全部
自动分类:关
5、一级不分类,二级自动分类
- 路径:/video
类型:电影
类别:全部
自动分类:开
- 路径:/video
类型:电视剧
类别:全部
自动分类:开
动漫独立一级目录示例:
1. 仅适用于v1.9.1-1+
2. 在分类策略配置文件中 movie/tv 下配置好动漫二级分类,anime配置项已弃用
3. 在目录设定中按如下格式新增目录,并提高优先级,仅为示例,同样的原理名称和路径都可以自己灵活调整,也可以不加(此时在电影/电视剧二级目录下)
- 路径:/video/动漫
类型:电影
类别:动画电影
- 路径:/video/动漫
类型:电视剧
类别:国漫
¶ 批量手动整理
当有较多命名类似的文件无法识别时(比如剧集有多集),往往需要批量手动整理,MoviePilot提供批量处理的方式以快速手动整理文件:
文件管理功能中选择一整个目录进行整理。历史记录中按关键字将某剧集相关的记录查询出来,全选后选择重新整理。
弹出整理对话框后,通过以下字段的使用实现批量整理功能:
-
自动重新整理:所有选项均不填,此时使用内置识别重新整理所有文件。
-
指定集数:无法识别出集数时直接指定集数,例如
1表示第1集,1-2表示第1-2集(两集合并为一个文件),1,3表示只处理第1到第3集的文件。 -
指定Part: 无法识别出Part时直接指定Part,需符合以下正则写法
(PART[0-9ABCI]{0,2}|^CD[0-9]{0,2}|^DVD[0-9]{0,2}|^DISK[0-9]{0,2}|^DISC[0-9]{0,2}),例如Part1,PartC,PartIII,Cd1,Dvd2,Disk10,Disc12。 -
集数定位:使用表达式来确定集数的位置,
{ep}占位符代表集数。例如:(BD)十二国記 第45話「東の海神 西の滄海 五章」(1440x1080 x264-10bpp flac).mkv、(BD)十二国記 第32話「風の万里 黎明の空 九章」(1440x1080 x264-10bpp flac).mkv共3个文件需要批量整理,此处可以填(BD)十二国記 第{ep}話{a}(1440x1080 x264-10bpp flac).mkv,{ep}表示集,{a}表示随意用一个变量来替代不需要的但又不一致的部分,如果除了集数外没有其余不一样的内容,则只标定{ep}就行。 -
集数偏移:对识别的集数做运算,以解决文件中集数与媒体元数据中的集数不一致的情况。例如
{ep}定位出集数是11, 实际是第1集, 此处填-10, 以应付多季合集的场景。对于需要复杂运算时,可使用EP代表识别出来的集数进行运算,如:EP*2-1。